table of contents
A clean pen test report can go stale in days.
When code ships daily, cloud settings shift, and identities spread across tools, a one-time assessment stops reflecting reality fast. That’s why continuous security testing matters more in 2026 than it did even two years ago.
A point-in-time test freezes a moving target
A scheduled assessment still has value. It can uncover deep flaws, validate controls, and support audits. However, it only tells you what was true during that testing window.
Modern environments don’t sit still. A new container image gets pushed. An engineer opens a security group for troubleshooting. A SaaS connector gains broader API access. A dormant subdomain comes back online. Each change can create fresh exposure after the report is signed off.
For a clear overview of continuous security testing, Praetorian explains the core issue well: periodic testing measures a moment, while your attack surface keeps changing.
A low-risk finding on test day can become a real attack path a week later.
This is why point-in-time testing often misses active risk. Active risk is what an attacker can reach, chain, or abuse now. In 2026, that window changes quickly because release cycles are shorter, cloud provisioning is automated, and external scanning by attackers is faster. A report from last quarter may still be useful for root-cause work, but it won’t tell you which path opened this morning.
Exposure drift shows up in cloud, identity, code, and third parties
The stale-report problem has a name, exposure drift. It happens when the environment changes faster than validation.
Here’s where that drift usually appears:
| Area | What changes between tests | Why it matters |
|---|---|---|
| Cloud | New buckets, routes, security groups | Internet exposure appears fast |
| Apps and APIs | Fresh endpoints, feature flags, auth flows | Logic and access gaps slip through |
| Identity | New role grants, stale service accounts | Privilege creep opens lateral paths |
| Third parties | Package updates, SaaS links, new domains | Supply chain and takeover risk grows |
Cloud teams see this every day. A storage bucket starts private, then a policy change makes data reachable. A test done before that change won’t catch the new state. The same goes for Kubernetes, serverless functions, and CI runners with broad secrets access.
Application security has its own version of drift. A secure build last month says little about today’s API surface. New business logic, a rushed hotfix, or a feature flag can expose paths that static review never saw. This is one reason teams keep moving toward continuous security validation instead of relying on a few checkpoints per year.
Identity is even trickier because trust changes quietly. A contractor keeps an old role. A service account gets reused in another pipeline. An IdP group sync grants admin rights through nested membership. None of that looks dramatic in change logs, yet it can create the cleanest path to impact. Meanwhile, attack surface management adds another layer. Marketing spins up a microsite, a vendor leaves behind a DNS record, or an unused hostname points to an abandoned SaaS tenant. Those assets may sit outside the scope of the last test, but attackers will still find them.
What continuous security testing changes in practice
Continuous security testing does not mean replacing all human-led testing with scanners. It means watching for change, validating exposure, retesting fixes, and ranking issues by exploitability and business impact.
That last part matters most. Security teams don’t need more findings. They need better proof of what is reachable, what can be chained, and what affects crown-jewel assets.
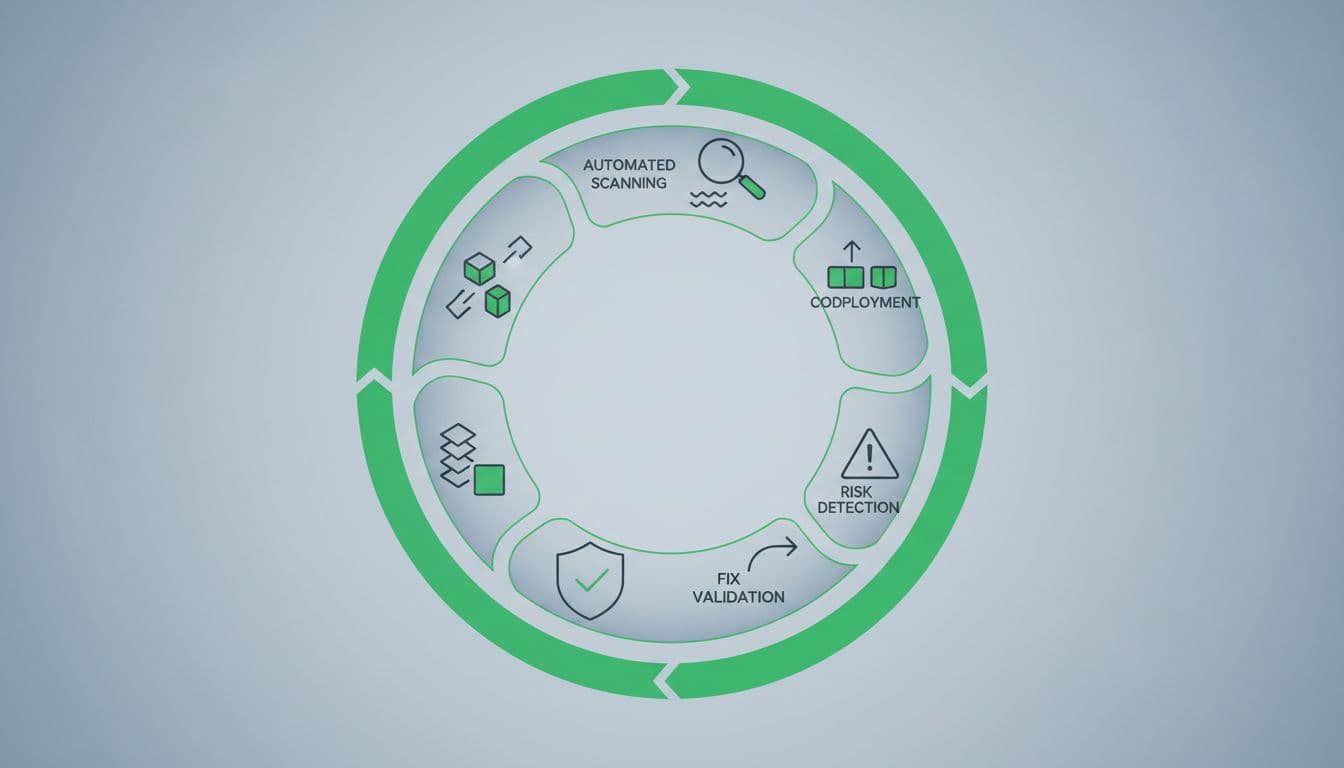
In practice, the model looks like this:
- Monitor change: Track new assets, config drift, identity changes, and code releases.
- Validate exposure: Confirm what is internet-reachable, exploitable, or chainable.
- Prioritize by context: Rank issues by blast radius, asset value, and attack path.
- Retest fixes fast: Verify that the remediation worked, then close the loop.
Consider a few examples. A firewall rule opens SSH to the internet on a non-production VPC. A snapshot test may miss it for months. Continuous validation catches the exposure, checks whether keys or identities make it useful, then pushes it up the queue if the VPC peers with production.
Or take AppSec. A new GraphQL mutation ships with weak authorization. Traditional testing may find it at the next scheduled review. Continuous testing tied to deployment changes can flag the new surface, exercise the auth path, and show whether the flaw reaches sensitive data.
The same applies to identity. If a CI service account gains admin rights in a cloud tenant, the real question is not whether that permission exists on paper. The question is whether it creates a live route to privileged actions, secrets, or lateral movement. A recent look at continuous pentesting requirements makes the point well: validation has to keep up with software change, or risk piles up between releases.
Human-led tests still matter, because people find chaining opportunities and business logic flaws that automation misses. Still, periodic depth should support continuous visibility, not replace it.
Point-in-time testing still has a place. It helps with deep review and formal assurance. But it can’t keep pace with active risk in environments that change every day.
Pull your last assessment report and compare it with today’s assets, identities, code, and vendors. If they no longer match, your testing model is behind your exposure.