table of contents
Your cloud attack surface can change before lunch. A new API ships through CI/CD, a forgotten SaaS admin token stays active, and a short-lived container exposes a service for 20 minutes, which is plenty of time for an attacker.
That’s why attack surface validation matters. It doesn’t stop at finding exposed assets. It checks whether those assets are reachable, risky, and worth fixing first.
For cloud-first teams, that difference shapes both daily priorities and board-level risk reporting.
What attack surface validation means when cloud changes by the hour
Attack surface validation asks a harder question than discovery alone: can an outsider reach this asset and use it right now? A one-time scan may flag an open port or public bucket. Validation checks the live path, the identity controls, the API behavior, and the likely blast radius. Think of it as testing the doors, not only counting them.
In cloud-first organizations, exposures appear through normal work. An AWS load balancer can publish a dev app. An Azure app registration can keep a stale client secret. A GCP Cloud Run service can accept traffic nobody expected. Add SaaS sprawl, preview environments, partner integrations, and machine identities from CI/CD, and the picture shifts by the hour.

Recent 2026 cloud incidents still follow the same pattern: public storage, weak MFA, exposed backup data, and untested API changes. The problem isn’t only visibility. It’s knowing which findings are real, reachable, and urgent.
If your inventory updates weekly, your exposure picture is already stale.
That’s why attack surface mapping and attack surface monitoring matter, but validation adds proof. It confirms real exposure with safe checks that won’t disrupt production.
This quick comparison helps frame the difference:
| Approach | Main job | Common gap |
|---|---|---|
| One-time scan | Finds known issues at one moment | Misses drift and live attack paths |
| Attack surface validation | Confirms reachability, identity weakness, API exposure, and attacker-usable paths | Needs strong ownership and response flow |
| Attack surface management | Runs the broader program for inventory, prioritization, remediation, and governance | Can become reporting-heavy without live proof |
Scanning finds clues, validation proves risk, and management turns that proof into a repeatable program.
How to evaluate tools and vendors without buying more noise
Not every CNAPP or EASM platform that claims validation does it well. Some still act like scanners with a newer label. When you compare tools, look past asset counts and dashboard polish. Ask how the platform handles AWS, Azure, GCP, and SaaS tenants. Then ask how it tracks domains, APIs, storage, and identities that change daily.
Strong tools usually share six traits:
- Live discovery: They catch ephemeral assets, serverless endpoints, preview apps, Kubernetes ingress, and shadow SaaS.
- Safe validation: They use non-destructive, rate-limited checks and keep evidence you can trust.
- Identity context: They map human and non-human identities, stale keys, risky app grants, and exposed SSO paths.
- API awareness: They test auth, version drift, forgotten routes, and public API docs that reveal too much.
- Workflow fit: They connect with ticketing, SIEM, IaC reviews, and CI/CD so owners can act quickly.
- Clear ownership: They show the cloud account, repo, team, and fix path, not only a raw IP address.
Good buying criteria from external ASM vendor guidance and ASM product selection advice point in the same direction. Discovery alone isn’t enough. Ask every vendor for a live pilot with known and unknown exposures. See whether it finds the orphaned subdomain, the exposed GraphQL endpoint, the public storage bucket, and the stale service principal.
Also press on identity. In 2026, machine identities from pipelines, integrations, and AI agents often create more risk than the server itself. Route SaaS access through a central identity hub when you can, then validate the grants around it. If the platform can’t validate SaaS logins, app grants, secret sprawl, and just-in-time access gaps, it will miss common attack paths.
A practical rollout framework for security teams
Rollouts fail when teams try to validate everything at once. Start where exposure meets business impact: internet-facing apps, login systems, public storage, remote admin paths, and APIs tied to customer or financial data.
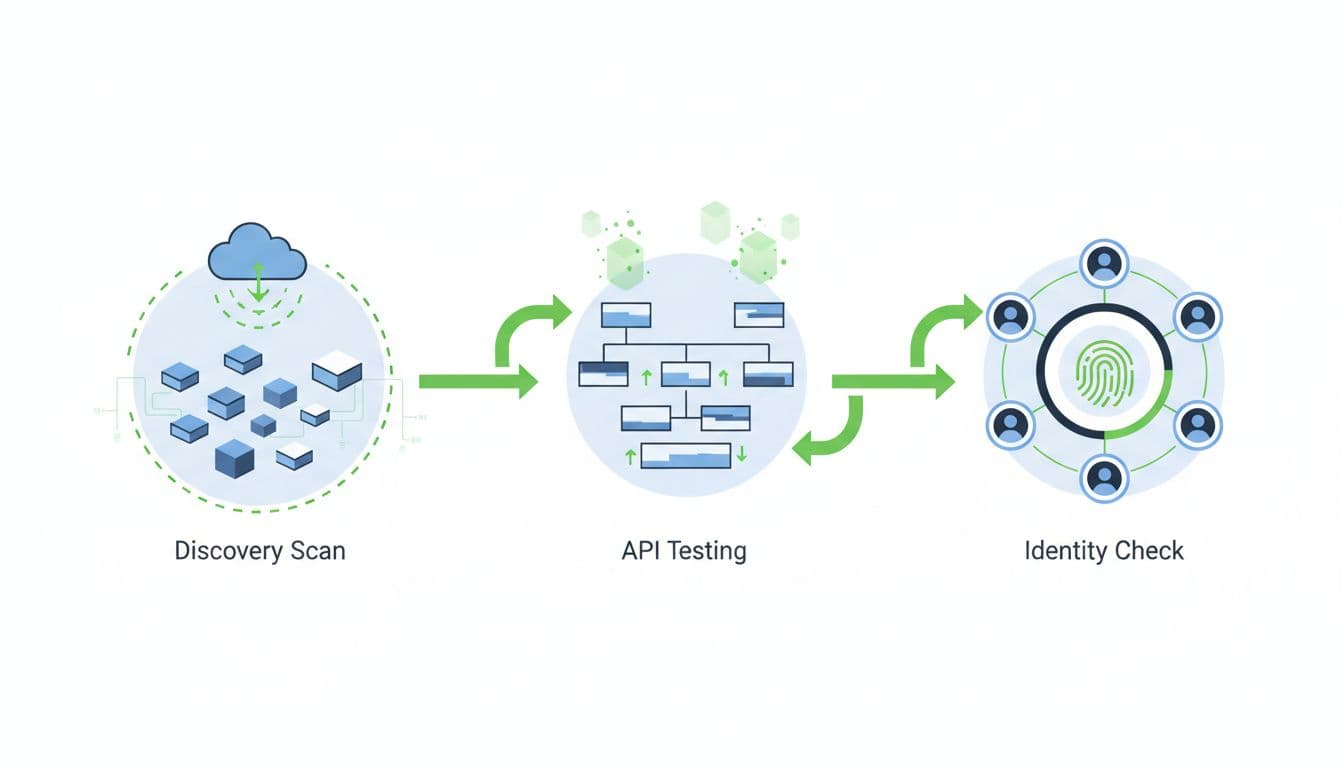
A workable rollout looks like this:
- Baseline the exposed edge: Inventory domains, subdomains, load balancers, CDN origins, APIs, SaaS tenants, and public cloud services. Tie each asset to an owner.
- Validate the highest-risk paths: Focus on auth flows, public storage, exposed admin panels, orphaned DNS, internet-facing Kubernetes ingress, and stale machine credentials.
- Wire it into delivery: Feed findings into CI/CD, IaC review, pull requests, and ticketing. When a new route appears, the owning team should see it before the weekly security meeting.
- Measure what gets better: Track validated exposures, time to remediate, repeat findings by team, asset ownership coverage, and reduced paths to Tier-0 systems.
Keep the first phase tight, usually one cloud account group, one identity platform, and one SaaS cluster. Then expand to third-party hosted apps, merger leftovers, and partner-connected APIs. Security owns the method, but platform, IAM, AppSec, and service teams must share the fix.
Cloud environments don’t stay still, so your exposure program can’t be static. The strongest teams treat attack surface validation as a live control, not a quarterly project.
Start small, prove value with validated findings, then widen coverage. If a finding can’t be reached, it shouldn’t drive the queue. If it can, fix it fast and close the loop.