
table of contents
Recent CVEs in ingress-nginx and Azure Kubernetes Service show how fast attackers hit container orchestration setups. You deploy pods at scale, but one weak spot lets them steal secrets or run code. These issues mix code flaws with team missteps.
Container orchestration security demands you spot exposures early. Misconfigurations top the list, yet vulnerabilities and design gaps add risk. This guide covers real steps to identify, fix, and watch them in Kubernetes clusters.
Start with access controls. They block most privilege jumps.
Lock Down Access with RBAC
Weak RBAC causes 40% of breaches in production clusters. Service accounts get cluster-admin by default in many setups. Attackers exploit this to escalate rights.
Enforce least privilege. Audit every RoleBinding and ClusterRoleBinding. Use namespace-scoped Roles for apps. Drop broad permissions like system:unauthenticated access.
Set runAsNonRoot: true on pods. Block privilege escalation with allowPrivilegeEscalation: false. Tools like kube-bench check this against CIS Kubernetes benchmarks.
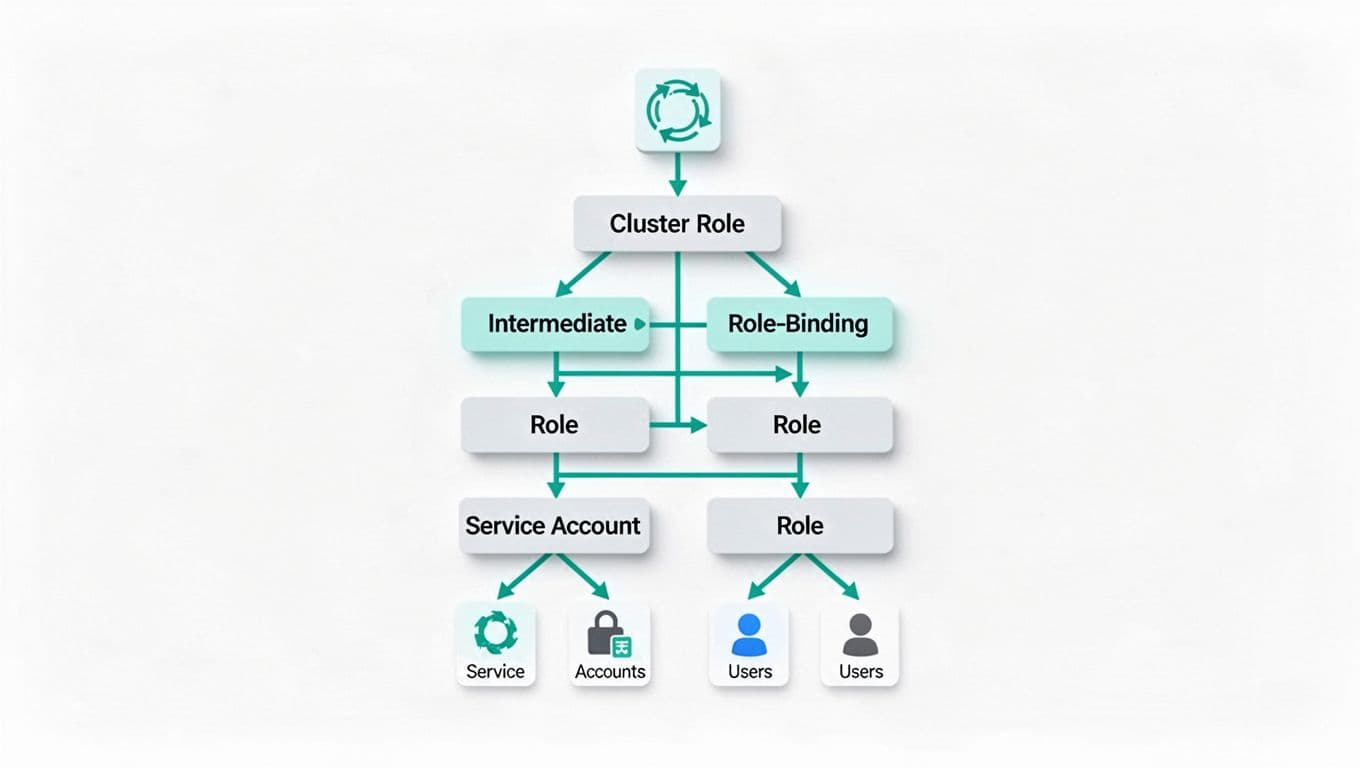
Workload identity helps too. Link pods to external IDs without long-lived tokens. In AKS, CVE-2026-33105 skipped auth because teams skipped this. Prioritize bindings by impact: fix cluster-admin first.
Remediate with policy-as-code. Kyverno or OPA Gatekeeper enforces RBAC rules on create. Scan weekly. Runtime tools alert on changes.
You cut exposure 80% this way. Next, traffic flows matter.
Control Traffic with Network Policies
Default Kubernetes networking allows all pod-to-pod talk. This architectural gap lets malware spread fast.
Apply default-deny policies per namespace. Allow only needed flows, like app to database on port 5432. Use labels for pods: app=frontend talks to app=backend.
Calico or Cilium enforce this. Check Kubernetes application security checklist for examples.
Ingress-nginx CVEs like CVE-2026-4342 hit because pods reached controllers unchecked. Identify with kubectl get networkpolicy. Prioritize production namespaces.
Test policies in staging. Block hostNetwork on pods. Monitor with Falco for odd connections.
Teams see lateral movement drop to near zero. Images bring supply chain risks now.
Secure Your Images and Supply Chain
Vulnerable images run everywhere. A single unpatched library exposes all pods.
Scan in CI/CD with Trivy or Grype. Fail builds on high CVEs. Sign images with cosign. Generate SBOMs via syft for full visibility.
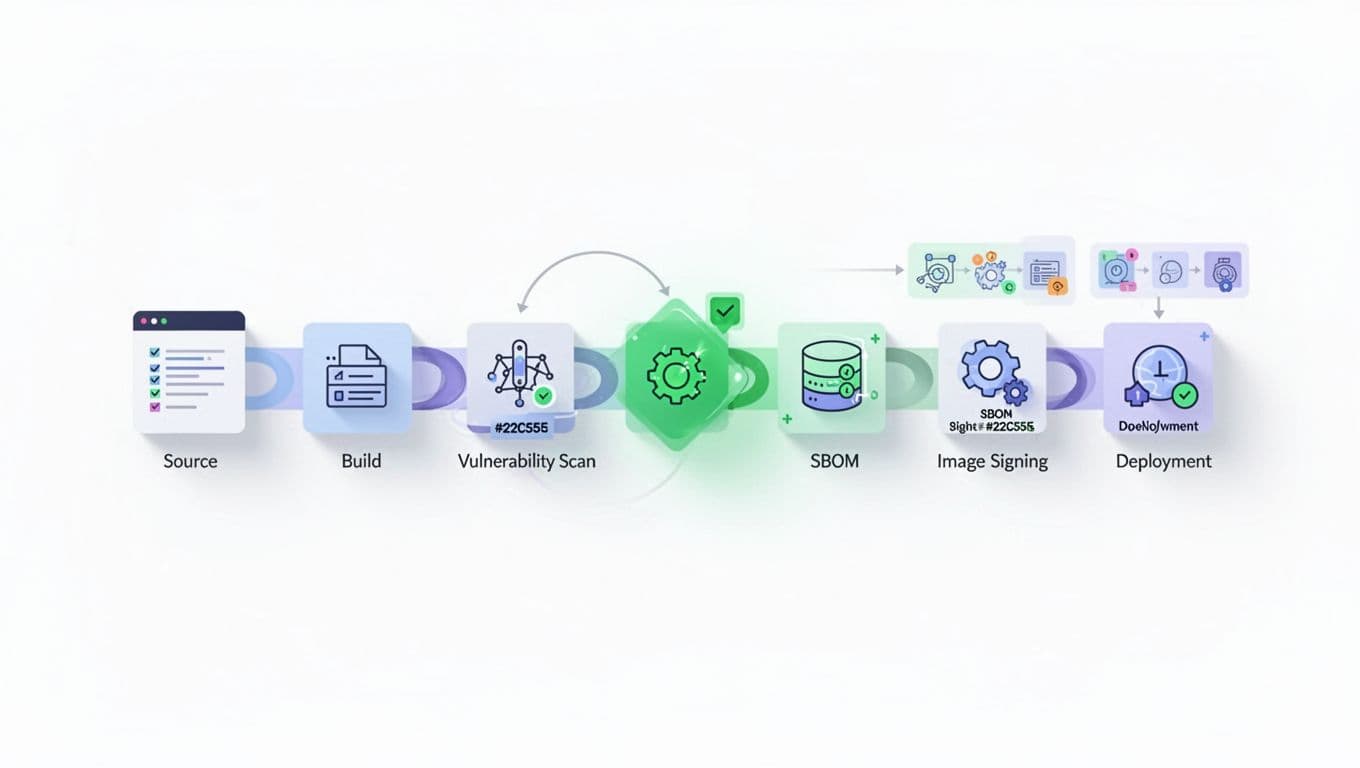
Use admission controllers like Gatekeeper. Reject unsigned or old images. Follow enterprise hardening checklists for read-only roots and dropped caps.
Distinguish: vulnerabilities in base images need patches; misconfigs like no limits cause DoS. Prioritize by exploitability score.
Pull from private registries. Rebuild quarterly. Runtime like Sysdig blocks exploits.
Supply chain attacks fell after teams added this. Secrets need the same care.
Manage Secrets Without Exposure
Secrets in etcd stay base64-encoded, not encrypted. Attackers with RBAC read them plain.
Use external vaults: HashiCorp Vault or AWS Secrets Manager. Inject at runtime via CSI drivers. Avoid Kubernetes Secrets for prod.
Enable etcd encryption at rest. Rotate keys yearly. Audit access logs.
Common scenario: dev pods mount prod secrets by mistake. Catch with production checklists. Tools like Trivy scan configs too.
Workload identity binds secrets to pods tightly. No static tokens. Remediate by migrating one namespace weekly.
You stop 90% of secret thefts. Policies tie it together.
Enforce Runtime and Admission Controls
Admission webhooks block bad pods upfront. Pod Security Standards (PSS) set restricted mode for prod. No root, no host paths.
Runtime detection spots anomalies. Falco or Tetragon watch syscalls. Alert on shell spawns or crypto mines.
Policy-as-code shines here. Define rules in Rego or YAML. Test with conftest.
Recent ingress flaws spread because no runtime blocks. Prioritize by cluster size: large ones first.
Scan with kube-hunter. Integrate to Slack for alerts. False positives drop after tuning.
Continuous checks keep you ahead.
Key Takeaways for Container Orchestration Security
Focus on RBAC, networks, and images first. They fix most exposures. Use PSS and runtime tools daily.
Vulnerabilities like CVE-2026-33105 demand patches now. Misconfigs need audits; architecture shifts to zero-trust.
Run weekly scans. Update best practices stay current.
Struggling with implementation? Book a Discovery Call with Bud Consulting to close gaps fast.
Your clusters run safer. Teams win when exposures stay managed.




