table of contents
Production Kubernetes clusters face constant threats. One misconfigured ingress exposes services to the world. Over-permissioned RBAC lets a compromised pod escalate privileges across the cluster. You know the drill because you’ve seen scans light up with alerts, but fixing them all takes forever.
CTEM in Kubernetes changes that. It shifts from endless vulnerability lists to workflows that spot real risks, validate them, and fix them fast. Security and platform teams collaborate on production priorities instead of fighting over tickets.
This article breaks down CTEM workflows tailored for your clusters. You’ll get practical steps with examples like RBAC gaps and runtime drift.
Key Risks in Production Kubernetes Clusters
Production clusters differ from dev ones. Scale amplifies issues. Exposed services top the list. An ingress without proper auth lets attackers probe endpoints directly.
RBAC over-permissioning follows close. Service accounts with cluster-admin bindings allow any pod to list secrets cluster-wide. Vulnerable container images compound this; a single unpatched pod in a multi-tenant namespace risks lateral movement.
Admission control gaps let bad deploys slip through. No policy blocks hostPath mounts or privileged containers. Insecure secrets handling, like base64-encoded env vars, leaks data on inspection. Workload identity issues arise when pods use overly broad IAM roles. Runtime drift happens post-deploy; configs change, breaking policies.
These risks hit production hard because workloads run live traffic. A 2026 OWASP Kubernetes Top 10 report flags overly permissive RBAC as a top issue. Teams waste time on low-impact alerts. CTEM workflows prioritize by business context. Start with internet-facing services, then internal paths.
Automation helps here. Tools scan manifests and runtime state continuously. But discovery alone fails without the full cycle. Next, map CTEM stages to your setup.
The CTEM Cycle in Kubernetes Environments
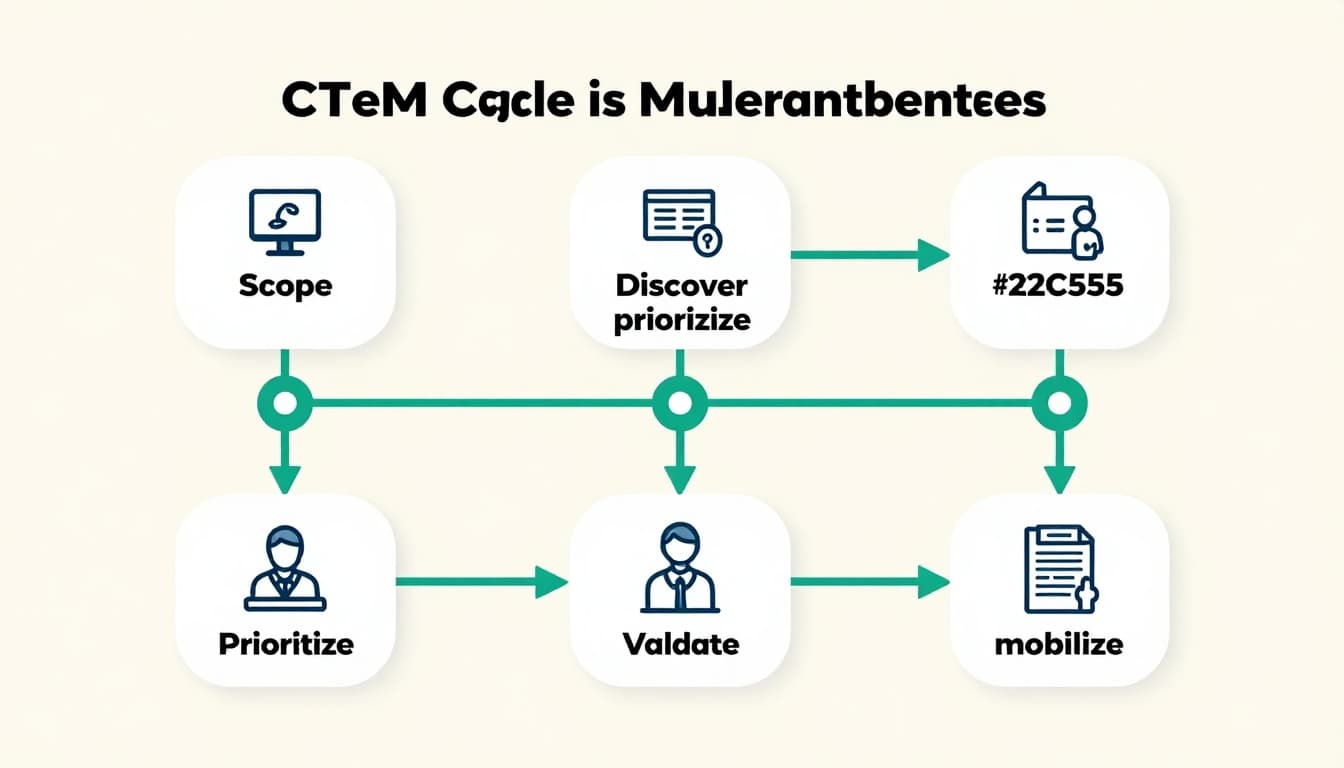
CTEM follows five stages: scope, discover, prioritize, validate, and mobilize. In Kubernetes, apply them weekly or on changes.
Scope defines your attack surface. Focus on prod namespaces first. List critical apps by revenue impact.
Discover finds issues. Scan for exposed ingresses via network policies. Check RBAC with tools like kubectl auth can-i.
Prioritize ranks by exploit likelihood. A high-CVE image in a low-traffic pod scores lower than RBAC admin on a database.
Validate tests real paths. Does that exposed service allow RCE? Simulate attacks without disruption.
Mobilize assigns fixes. Platform teams update manifests; security validates.
This loop runs continuously. Gartner’s 2026 CTEM guidance stresses starting small. Pick one namespace. Run a cycle. Measure time to fix. Scale out. Kubernetes fits perfectly because APIs expose everything programmatically.
Integrate with existing tools. Use Falco for runtime, Trivy for images. The cycle ensures you act, not just alert.
Scoping Your Kubernetes Attack Surface
Scope sets boundaries. Don’t boil the ocean. In prod clusters, start with external exposures.
List ingresses and load balancers. kubectl get ingress -A shows public endpoints. Tag them by app criticality. Payments namespace gets top priority.
Include identities. Service accounts tied to cloud IAM count as scope. Overly broad roles amplify risks.
Internal paths matter too. Pod-to-pod attacks via misconfigured network policies. Scope by business unit. Finance team owns their workloads.
Use node selectors for isolation. Dedicate nodes to high-trust apps. This narrows scope during discovery.
In 2026, best practices recommend eBPF-based CNIs like Cilium for visibility. They map flows automatically. Scope covers 90% of assets in days, not months.
Teams often skip this. Result? Wasted scans on test clusters. Define scope in a shared doc. Review quarterly. This keeps workflows focused.
Discovering Exposures in Running Clusters
Discovery scans everything. Start with static checks on manifests.
Tools like kube-bench run CIS benchmarks. They flag anon auth disabled or etcd unencrypted.
Runtime scans catch drift. Pods pulling unvetted sidecars. Use OPA Gatekeeper for policy-as-code.
Exposed services show in kubectl get svc -o wide. Filter for LoadBalancer types without restrictions.
RBAC issues: Audit bindings. kubectl auth reconcile finds excessive verbs like create on secrets.
Vulnerable images: Clair or Trivy in cron jobs. Scan registries too.
Secrets: Detect env vars or volumes mounting kube secrets plainly.
Stream Security’s CTEM post details integrating these. Automate via operators. Discovery feeds prioritization directly.
False positives drop with context. A vuln in a read-only pod matters less. Log findings to a central dashboard. Share with platform teams daily.
Prioritizing Risks by Real Impact
CVSS scores mislead. A 9.8 in a non-reachable pod wastes effort. Prioritize by reachability and blast radius.
For exposed services, check if they face the internet. Use external scanners.
RBAC: Score by who holds admin. A team service account beats user ones.
Images: Weigh by runtime hours and privileges.
Admission gaps: Test deploy frequency. Frequent deploys need strong gates.
Use a matrix. Reachability x severity x business value.
| Factor | Low | Medium | High |
|---|---|---|---|
| Reachability | Internal only | Cluster-internal | Internet-facing |
| Severity | CVSS <5 | CVSS 5-8 | CVSS >8 |
| Value | Dev | Staging | Prod revenue |
This table guides tickets. High-high-high goes first. Automation scores via scripts. Platform teams fix top 10 weekly.
2026 metrics show CTEM cuts MTTR by 50%. Focus here pays off.
Validating Kubernetes Exposures for Exploitability
Scans lie. Validate with active tests.
For RBAC, use kubectl auth can-i –as=sa-name. Simulate escalations.
Exposed services: Curl from outside. Check auth bypasses.
Images: Run in a sandbox pod. Attempt exploits.
Admission: Try bad manifests. Does Gatekeeper block?
Secrets: Inspect mounted volumes.
Workload identities: Check token scopes against needs.
Tools like Kube-hunter automate this. It probes without harm.
Validation cuts noise by 84%, per recent data. Distinguish findings from exploits. Only mobilize validated ones.
Security runs these; platform confirms. Loop closes gaps fast.
Cross-Team Workflows for Detection and Remediation
Security discovers; platform remediates. Align them.
Weekly standups review top risks. Security presents validated exposures. Platform estimates fix time.
Use Jira or GitHub issues. Link to cluster events.
For RBAC, platform audits bindings quarterly. Security validates post-fix.
Exposed services: Network team adds policies. Test together.
Automation bridges gaps. Webhooks notify Slack on drifts.

Ktrust’s Kubernetes CTEM guide shows orchestration examples. Embed fixes in IaC. Teams own namespaces.
This builds trust. Fixes land faster.
Handling Runtime Drift and Workload Identities
Runtime kills static scans. Pods drift via configmaps or env changes.
Monitor with Prometheus. Alert on spec diffs.
Admission controllers prevent drifts upfront. Kyverno mutates bad deploys.
Workload identities: Use IRSA or federated tokens. Avoid long-lived keys.
Gaps let pods impersonate broad roles.

Google’s RBAC best practices stress least privilege. Validate token flows in CTEM.
Fix drifts with rolling restarts. Automate rollbacks.
CTEM in CI/CD Pipelines
Shift left with gates.
Pre-commit: Trivy scans images.
Build: Policy checks on manifests.
Deploy: Admission webhooks.
Post-deploy: Runtime validation.
ArgoCD enforces drift-free deploys. Fail builds on RBAC excesses.
Palo Alto’s CTEM overview ties this to mobilization. Gates block 90% issues early.
Teams iterate manifests safely.
2026 Best Practices and Automation
Separate workloads by trust. Use namespaces per env and team.
Harden per CIS. Encrypt etcd, RBAC least privilege.
Zero trust everywhere. eBPF for networks.
Automate metrics: MTTD under hours, validation >80%.
Kyverno vs Gatekeeper comparison helps pick tools.
If gaps persist, book a discovery call with Bud Consulting. They vet experts for complex setups.
Conclusion
CTEM workflows secure Kubernetes clusters by focusing on real threats. You scope critical assets, discover exposures like RBAC flaws, prioritize by impact, validate exploits, and mobilize fixes across teams.
Production stays safe with runtime monitoring and CI/CD gates. Breaches drop; teams move fast.
Apply one stage this week. Your cluster thanks you.